Database software is everywhere, quietly powering everything from your social media feed to your bank account. It’s the backbone of modern computing, allowing us to store, manage, and retrieve massive amounts of information efficiently. This exploration delves into the core functionalities, various types, and crucial considerations involved in selecting and utilizing this essential technology. We’ll cover everything from relational databases to NoSQL solutions, SQL queries to cloud-based options, and even touch on the increasingly important aspects of data security and visualization.
Get ready to level up your database game!
We’ll explore the different types of database management systems (DBMS), like MySQL, PostgreSQL, Oracle, and MongoDB, examining their strengths and weaknesses. We’ll also look at the design process, from creating Entity-Relationship Diagrams (ERDs) to writing efficient SQL queries and ensuring data integrity. The journey will cover crucial topics like data modeling, security, and the exciting world of cloud-based database solutions.
Think of it as your crash course in becoming a database whiz.
Defining Database Software
Database software is, in essence, a system designed to organize, store, and retrieve data efficiently. Think of it as a highly structured filing cabinet, but instead of paper files, it manages digital information. This allows for easy access, modification, and analysis of large volumes of data, making it a crucial component in nearly every modern application, from simple to-do lists to complex financial systems.Database software achieves this through several core functionalities.
It provides mechanisms for creating, modifying, and deleting data; ensuring data integrity through validation and consistency checks; managing user access and permissions; and offering query languages to retrieve specific information efficiently. These features work together to provide a reliable and secure way to manage information.
Database Management Systems (DBMS) Examples
Several different Database Management Systems (DBMS) are available, each with its own strengths and weaknesses. Choosing the right DBMS depends on factors like the size of the database, the type of data being stored, and the performance requirements. Popular examples include MySQL, a widely used open-source relational database system; PostgreSQL, another robust open-source relational database known for its advanced features; Oracle Database, a commercial enterprise-grade system known for its scalability and reliability; and MongoDB, a popular NoSQL document database.
Each of these systems offers a different set of tools and capabilities tailored to specific needs.
Database Types
Databases can be broadly categorized into several types, with relational and NoSQL databases being the most prominent. Relational databases, like MySQL and PostgreSQL, organize data into tables with rows and columns, establishing relationships between different tables through keys. This structured approach ensures data consistency and integrity. In contrast, NoSQL databases offer more flexible schemas and are often better suited for handling large volumes of unstructured or semi-structured data.
Examples of NoSQL databases include MongoDB (document database), Cassandra (wide-column store), and Neo4j (graph database). The choice between relational and NoSQL depends heavily on the application’s requirements.
Comparison of Database Models
The differences between relational and NoSQL databases extend beyond their schema flexibility. Relational databases emphasize data integrity and consistency through ACID properties (Atomicity, Consistency, Isolation, Durability), guaranteeing reliable transactions. NoSQL databases, on the other hand, often prioritize scalability and availability, sometimes sacrificing some level of consistency. For example, a relational database might be ideal for a banking application where transaction accuracy is paramount, while a NoSQL database might be preferred for a social media platform where high availability is crucial even if minor inconsistencies occasionally occur.
The trade-offs between consistency, availability, and partition tolerance (CAP theorem) are central to this comparison. Choosing the appropriate model is crucial for application success.
Choosing the Right Database Software
Picking the perfect database system feels like choosing a superhero for your data – you need one that’s got the right powers for the job. The wrong choice can lead to slowdowns, security vulnerabilities, and headaches galore. So, let’s dive into what you need to consider.
Factors to Consider When Selecting Database Software
Selecting the right database hinges on several key factors. Understanding your application’s needs, data volume, and future scalability are crucial. Consider the type of data you’ll be storing (structured, semi-structured, or unstructured), the frequency of data access, and the required level of data consistency and availability. Security is also paramount; choose a system with robust access controls and encryption features.
Finally, think about your team’s expertise – do you have the skills to manage a complex system, or would a simpler, more user-friendly option be better?
Performance Characteristics of Different Database Systems
Different database systems excel in different areas. Relational databases (like MySQL, PostgreSQL, and Oracle) are great for structured data and complex queries, offering ACID properties (Atomicity, Consistency, Isolation, Durability) for reliable transactions. NoSQL databases (like MongoDB, Cassandra, and Redis), on the other hand, are better suited for handling large volumes of unstructured or semi-structured data and offer high scalability and availability.
In-memory databases (like Memcached and Redis) prioritize speed, ideal for caching frequently accessed data. The best choice depends heavily on your application’s performance requirements. For instance, a high-volume e-commerce site might benefit from the scalability of a NoSQL database, while a banking application might require the ACID properties of a relational database for transaction integrity.
Comparison of Open-Source and Proprietary Database Systems
| Feature | Open-Source (e.g., MySQL, PostgreSQL) | Proprietary (e.g., Oracle, Microsoft SQL Server) |
|---|---|---|
| Cost | Generally free to use, but may involve costs for support and specialized services. | Typically involves licensing fees, often dependent on the number of users or processors. |
| Customization | High degree of flexibility and customization; you can modify the source code. | Limited customization options; changes usually require vendor support. |
| Support | Community-based support; commercial support options are available. | Usually includes comprehensive vendor support and maintenance agreements. |
| Scalability | Highly scalable, especially with cloud-based deployments; scalability can require more specialized expertise. | Generally highly scalable, with vendor-provided tools and support for large deployments. |
Scalability and Cost Considerations
Scalability is crucial – can your database handle growth in data volume and user traffic? Cloud-based solutions offer excellent scalability, allowing you to easily increase resources as needed. However, cloud services can be expensive, especially at high usage levels. On-premises solutions provide more control but require significant upfront investment in hardware and infrastructure. Cost considerations also involve factors like licensing fees (for proprietary systems), support contracts, and the cost of skilled personnel to manage the database.
For example, a small startup might start with a cost-effective open-source solution like MySQL, while a large enterprise might opt for a scalable proprietary solution like Oracle, despite the higher cost, due to its robust features and support.
Data Modeling and Design
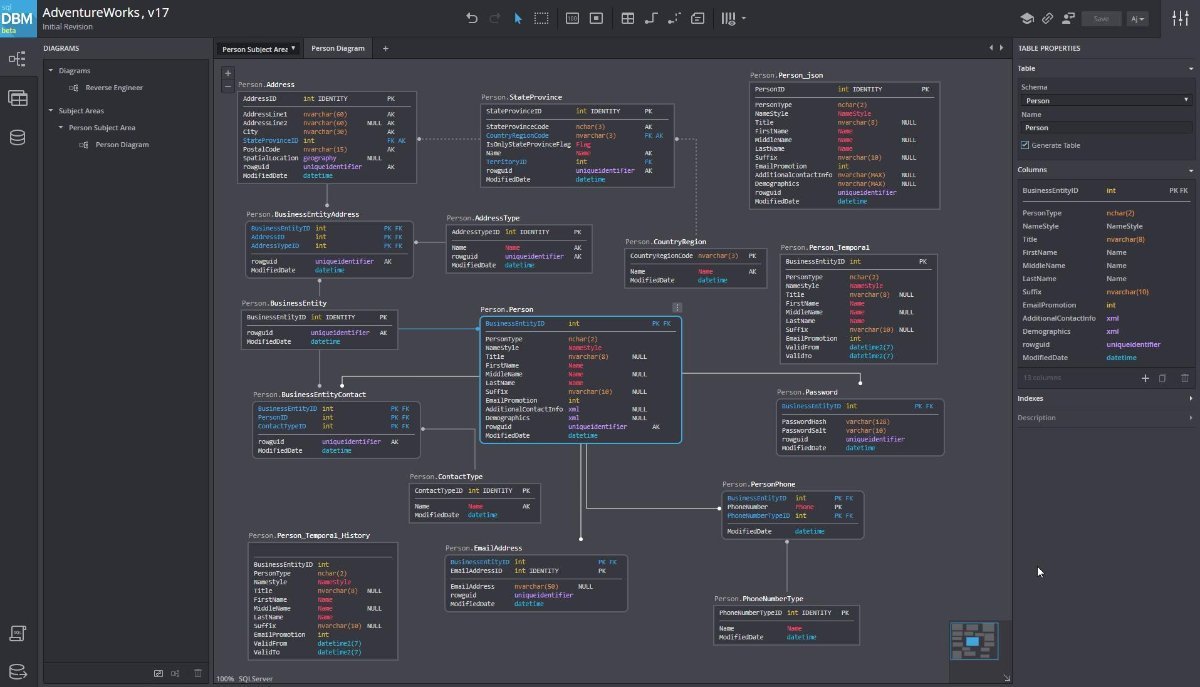
Okay, so we’ve picked our database software, right? Now it’s time to get our hands dirty with the actual structure of the data. Data modeling and design is basically the blueprint for your database – it dictates how your information is organized and how different pieces relate to each other. Get this wrong, and you’ll be wrestling with a messy, inefficient database later.
Think of it as the foundation of a house – you wouldn’t start building without a solid plan, would you?Data modeling is all about creating a visual representation of your data, showing how different entities (things like customers, products, orders) interact. This helps you understand relationships and dependencies before you start writing any code. A crucial part of this is choosing the right data model and normalization techniques to ensure data integrity and efficiency.
Entity-Relationship Diagrams (ERDs)
An Entity-Relationship Diagram (ERD) is a visual representation of the entities within an information system and the relationships between those entities. Let’s say we’re building a database for an online bookstore. We might have entities like “Customers,” “Books,” and “Orders.” The ERD would show how these entities relate – for example, a customer can place many orders, and each order contains multiple books.
A simple ERD would depict these entities as rectangles, with lines connecting them to illustrate the relationships. For example, a line connecting “Customers” and “Orders” would indicate a one-to-many relationship (one customer can have many orders). Attributes (like customer name, book title, order date) would be listed within each entity rectangle. The cardinality (one-to-one, one-to-many, many-to-many) of each relationship would be clearly defined, usually using notation like crows feet or numbers.
This visual representation provides a clear and concise overview of the database structure.
Data Normalization
Data normalization is a process used to organize data to reduce redundancy and improve data integrity. It’s all about minimizing data duplication, which can lead to inconsistencies and wasted space. There are several normal forms (like 1NF, 2NF, 3NF, and BCNF), each addressing different types of redundancy. For instance, storing a customer’s address multiple times for each order they place is redundant.
Normalization would break this down, storing the address only once in the “Customers” table and linking it to the “Orders” table through a customer ID. This makes updates easier and prevents inconsistencies – if the customer moves, you only need to update their address in one place. The goal is to create a database that is efficient, consistent, and easy to maintain.
Database Design and Implementation
Designing and implementing a database involves several key steps. First, you define the scope of the project and the requirements. Then, you create a conceptual model (usually an ERD), refining it through multiple iterations. This model guides the logical design, where you choose specific database structures and data types. The physical design involves selecting a specific database system (like MySQL, PostgreSQL, or MongoDB) and optimizing the database for performance.
Implementation involves creating the database, defining tables, and loading the data. Testing and refinement are crucial throughout the entire process. For example, you might start with a simple ERD, then refine it based on feedback and testing, before finally implementing the optimized design in your chosen database system.
Data Modeling Techniques
Several data modeling techniques exist, each with its strengths and weaknesses. The Entity-Relationship Model (ERM), which uses ERDs, is widely used for relational databases. Object-Oriented Modeling is suitable for object-oriented databases, focusing on objects and their relationships. NoSQL databases often use schema-less models, offering more flexibility but potentially less data integrity. The choice of technique depends on the specific needs of the project and the type of database being used.
For example, a simple inventory management system might use a basic ERM, while a complex social media platform might benefit from a more sophisticated object-oriented model or a NoSQL approach depending on its scale and requirements.
SQL and Database Queries
Okay, so we’ve covered the basics of databases. Now let’s dive into the heart of interacting with them: SQL (Structured Query Language). Think of SQL as the language you use to talk to your database – to ask for information, add new data, update existing entries, or delete stuff. It’s pretty powerful and surprisingly straightforward once you get the hang of it.SQL uses various commands to manipulate data.
These commands are structured in a specific way to ensure the database understands what you want. We’ll look at some key commands and clauses that form the foundation of most SQL queries.
Common SQL Query Types
SQL offers several fundamental commands for interacting with data. These commands allow you to retrieve, insert, modify, and delete information within your database. Mastering these commands is crucial for effectively managing your database.
- SELECT: This command retrieves data from one or more tables. For example, `SELECT
– FROM Customers;` retrieves all columns and rows from the ‘Customers’ table. A more specific query might be `SELECT FirstName, LastName FROM Customers WHERE Country = ‘USA’;` which retrieves only the first and last names of customers from the USA. - INSERT: This command adds new rows to a table. For example, `INSERT INTO Customers (FirstName, LastName, Country) VALUES (‘John’, ‘Doe’, ‘Canada’);` adds a new customer record.
- UPDATE: This command modifies existing rows in a table. For example, `UPDATE Customers SET Country = ‘Mexico’ WHERE CustomerID = 1;` changes the country of the customer with ID 1 to Mexico.
- DELETE: This command removes rows from a table. For example, `DELETE FROM Customers WHERE CustomerID = 1;` deletes the customer with ID 1.
SQL Clauses
SQL clauses refine your queries, allowing you to filter, sort, and group results. They add precision and efficiency to your data retrieval.
- WHERE: This clause filters the results based on a specified condition. It’s used with SELECT, UPDATE, and DELETE statements. For example, `SELECT
– FROM Products WHERE Price > 100;` returns only products with a price greater than 100. - ORDER BY: This clause sorts the results based on one or more columns. For example, `SELECT
– FROM Customers ORDER BY LastName;` sorts the customers alphabetically by last name. - GROUP BY: This clause groups rows with the same values in one or more columns. It’s often used with aggregate functions like SUM, AVG, COUNT. For example, `SELECT Country, COUNT(*) FROM Customers GROUP BY Country;` counts the number of customers in each country.
- HAVING: This clause filters grouped results based on a condition. It’s used with GROUP BY. For example, `SELECT Country, COUNT(*) FROM Customers GROUP BY Country HAVING COUNT(*) > 10;` shows only countries with more than 10 customers.
Best Practices for Efficient SQL Queries
Writing efficient SQL is key to database performance. Here are some tips:
- Use indexes: Indexes speed up data retrieval. Create indexes on frequently queried columns.
- Avoid using SELECT
-: Specify the columns you need. Retrieving all columns is inefficient. - Optimize WHERE clauses: Use appropriate data types and avoid using functions within WHERE clauses if possible.
- Use joins carefully: Overuse of joins can slow down queries. Consider using subqueries or other techniques when appropriate.
A Complex SQL Query Example
Let’s say we have two tables: `Orders` (OrderID, CustomerID, OrderDate, TotalAmount) and `Customers` (CustomerID, FirstName, LastName, City). We want to find the total amount spent by customers from ‘New York’ in the last month.
SELECT SUM(o.TotalAmount) AS TotalSpent FROM Orders o JOIN Customers c ON o.CustomerID = c.CustomerID WHERE c.City = 'New York' AND o.OrderDate >= DATE('now', '-1 month');
This query joins the `Orders` and `Customers` tables, filters for customers from New York and orders from the last month, and then sums the total amounts. It’s a good example of combining multiple clauses and joins to retrieve specific, aggregated data.
Data Integrity and Validation

Data integrity is the accuracy, consistency, and reliability of data. It’s crucial for any database, ensuring that the information stored is trustworthy and usable for decision-making. Without robust data integrity measures, your database becomes vulnerable to errors, inconsistencies, and ultimately, unreliable results. Maintaining data integrity requires a multifaceted approach involving both preventative measures and reactive checks.Data validation techniques are the specific methods used to ensure data integrity.
These techniques verify that data meets predefined rules and constraints before it’s accepted into the database. This preventative approach minimizes the risk of erroneous data entering the system and polluting the overall dataset. Effective validation is a key component of a robust database system.
Methods for Ensuring Data Integrity, Database software
Maintaining data integrity involves a combination of strategies. These strategies work together to create a system that minimizes errors and ensures data reliability. A comprehensive approach is essential for ensuring data quality.
- Constraints: Database constraints, such as NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY, and CHECK constraints, enforce rules about the data that can be stored in a table. For example, a NOT NULL constraint ensures that a specific column cannot contain null values, while a FOREIGN KEY constraint ensures referential integrity between tables.
- Data Validation Rules: These rules are implemented at the application level and check data before it’s even submitted to the database. This might involve checking data types, ranges, formats, and performing more complex logical checks. For instance, a rule might ensure that an age field is a positive integer and less than 120.
- Stored Procedures and Triggers: Stored procedures and triggers are database objects that can be used to enforce data integrity rules at the database level. Triggers automatically execute in response to specific database events (like INSERT, UPDATE, or DELETE), allowing for real-time validation and data manipulation. A trigger might prevent the deletion of a record if it’s referenced by other tables.
- Data Cleansing and Transformation: This involves identifying and correcting inconsistencies, inaccuracies, and incomplete data already present in the database. This is often a more involved process that might require specialized tools and techniques.
Data Validation Techniques
Several specific techniques are employed for validating data. These techniques range from simple checks to more complex algorithms, depending on the data and its context.
- Data Type Validation: Ensuring that the data entered matches the expected data type (e.g., integer, string, date). For example, preventing text from being entered into a numerical field.
- Range Validation: Verifying that numerical data falls within an acceptable range. For example, ensuring that an age is between 0 and 120.
- Format Validation: Checking that data conforms to a specific format (e.g., email address, phone number). For example, verifying that an email address contains “@” and a domain.
- Length Validation: Ensuring that data does not exceed a specified length. For example, limiting the length of a name field to 50 characters.
- Cross-Field Validation: Checking for consistency between multiple fields. For example, ensuring that the start date is before the end date.
- Lookup Validation: Verifying that a value exists in a predefined list or another table. For example, checking that a state abbreviation exists in a list of valid state abbreviations.
Common Data Integrity Issues and Their Solutions
Several common problems can compromise data integrity. Understanding these issues and their solutions is vital for building reliable databases.
- Duplicate Data: UNIQUE constraints prevent duplicate entries. Data cleansing processes can identify and remove existing duplicates.
- Missing Data: NOT NULL constraints prevent missing values in crucial fields. Business rules might require default values or data imputation techniques.
- Inconsistent Data: Data standardization and validation rules help maintain consistency. Data cleansing might be needed to correct existing inconsistencies.
- Invalid Data: Data validation techniques, including range checks and format validation, prevent invalid data from entering the database. Data cleansing can also address pre-existing invalid data.
- Referential Integrity Issues: FOREIGN KEY constraints maintain referential integrity. Triggers can prevent actions that violate referential integrity.
Design Constraints to Enforce Data Integrity
Database design plays a critical role in maintaining data integrity. Constraints are essential tools in this process.
Properly defined constraints act as the first line of defense against corrupted data. By incorporating these constraints during the database design phase, developers proactively prevent many common data integrity issues. This proactive approach is far more efficient and cost-effective than trying to fix problems after they occur.
- PRIMARY KEY Constraints: Uniquely identify each record in a table. Ensures each record is distinct and can be easily referenced.
- FOREIGN KEY Constraints: Establish relationships between tables, maintaining referential integrity. Prevents orphaned records and ensures data consistency across related tables.
- UNIQUE Constraints: Ensure that a column or set of columns contains only unique values. Prevents duplicate entries and maintains data accuracy.
- NOT NULL Constraints: Prevent null values in specified columns. Ensures that essential data is always present.
- CHECK Constraints: Enforce specific conditions on the data in a column. Allows for customized validation rules beyond basic data types and relationships.
Database Administration
Okay, so you’ve got your database up and running, but now what? That’s where the Database Administrator (DBA) comes in. Think of them as the unsung heroes, keeping everything humming along smoothly behind the scenes. They’re responsible for the overall health, performance, and security of your entire database system.Database administration is a multifaceted role demanding a blend of technical skills and strategic thinking.
DBAs are crucial for ensuring data integrity, availability, and efficient use of resources. Their work directly impacts the success of any organization relying on data-driven operations.
Responsibilities of a Database Administrator
DBAs wear many hats. Their responsibilities span planning, implementation, maintenance, and troubleshooting of database systems. This includes tasks like installing and configuring database software, designing and implementing database schemas, ensuring data security through access controls and encryption, and optimizing database performance to meet application demands. They also handle user account management, data backups and recovery, and resolving database-related issues.
Essentially, they’re the guardians of your precious data.
Database Performance Monitoring and Tuning
Keeping a database running efficiently is key. Performance monitoring involves using tools to track key metrics like query response times, resource utilization (CPU, memory, I/O), and overall system throughput. If performance lags, DBAs use various tuning techniques to improve things. This might involve optimizing database queries, adding indexes, adjusting database configurations, or even upgrading hardware. For example, identifying a slow-running query that impacts an e-commerce website’s checkout process and optimizing it can drastically reduce customer wait times and improve conversion rates.
Database Security Best Practices
Data security is paramount. DBAs implement security measures to protect sensitive information from unauthorized access, use, disclosure, disruption, modification, or destruction. This includes implementing strong password policies, using encryption to protect data both in transit and at rest, regularly auditing database activity, and implementing access control mechanisms like role-based permissions. They also stay up-to-date on the latest security threats and vulnerabilities and implement appropriate countermeasures.
For instance, regularly patching the database software to address known vulnerabilities is crucial in preventing exploitation.
Regular Database Maintenance Checklist
Proactive maintenance is essential for preventing issues before they arise. A regular maintenance schedule should include tasks like:
- Regular Backups: Creating full and incremental backups at defined intervals to ensure data recoverability in case of failures.
- Performance Monitoring: Continuously tracking key performance indicators to identify and address potential bottlenecks.
- Security Audits: Regularly reviewing access controls and permissions to identify and address potential security vulnerabilities.
- Log Management: Monitoring database logs to detect and address errors and unusual activity.
- Space Management: Regularly reviewing disk space usage and implementing strategies to manage storage efficiently.
- Software Updates: Applying patches and updates to the database software to address bugs and security vulnerabilities.
- Index Optimization: Regularly reviewing and optimizing database indexes to improve query performance.
- Schema Review: Periodically reviewing the database schema to identify and remove redundant or obsolete data.
Following a consistent maintenance schedule minimizes downtime, improves performance, and safeguards against data loss. A well-maintained database is a happy database.
Database Security and Access Control
Database security is paramount; without robust security measures, your data is vulnerable to unauthorized access, modification, or deletion, leading to potential breaches, financial losses, and reputational damage. Effective security relies on a multi-layered approach encompassing authentication, authorization, encryption, and preventative measures against attacks like SQL injection.
Authentication Methods
Authentication verifies the identity of a user attempting to access the database. Common methods include passwords, multi-factor authentication (MFA), and digital certificates. Passwords, while simple, are vulnerable to cracking. MFA adds an extra layer of security, requiring multiple forms of verification, such as a password and a one-time code sent to a mobile device. Digital certificates provide strong authentication using public key cryptography, often used in enterprise environments.
Authorization Methods
Authorization determines what a user can do once authenticated. This is typically managed through access control lists (ACLs) or role-based access control (RBAC). ACLs grant specific permissions to individual users or groups for specific database objects. RBAC, however, is more efficient for managing permissions in larger systems.
Role-Based Access Control (RBAC)
RBAC assigns users to predefined roles, each with a specific set of permissions. For example, a “data analyst” role might have read access to all tables but no write access, while a “database administrator” role would have full control. This simplifies permission management, improves security by reducing the number of individual permissions to manage, and promotes consistency in access control.
Changes to permissions only need to be made at the role level, affecting all users assigned to that role.
Encryption Techniques
Encryption protects data at rest and in transit. Data at rest refers to data stored on the database server’s hard drives. Data in transit refers to data being transferred between the database server and client applications. Common encryption techniques include symmetric encryption (using the same key for encryption and decryption) and asymmetric encryption (using separate keys for encryption and decryption).
Database systems often use a combination of both. For example, symmetric encryption might be used to encrypt the data itself, while asymmetric encryption is used to protect the symmetric key. This ensures that even if the symmetric key is compromised, the data remains secure.
Preventing SQL Injection Attacks
SQL injection attacks exploit vulnerabilities in database applications to execute malicious SQL code. A common preventative measure is parameterized queries or prepared statements. These separate user-supplied data from the SQL code, preventing malicious code from being interpreted as SQL commands. Input validation, carefully checking user-supplied data for unexpected characters or data types, is also crucial. Escaping special characters within user input can further mitigate the risk, but parameterized queries are generally considered the most robust solution.
Regular security audits and penetration testing are essential for identifying and addressing potential vulnerabilities before they can be exploited.
Cloud-Based Database Solutions: Database Software
Okay, so we’ve covered the basics of databases. Now let’s talk about the cloud – specifically, how cloud services are changing the database game. Think of it as moving your entire database from your own server room (or your laptop!) to a massive, super-secure data center managed by a company like Amazon, Microsoft, or Google. It’s a big shift, but with significant upsides and downsides we need to consider.Cloud databases offer a scalable, flexible, and often cost-effective alternative to traditional on-premises solutions.
But choosing the right cloud provider and managing the transition requires careful planning and understanding of the trade-offs involved. We’ll explore the major players, weigh the pros and cons, and delve into the migration process.
Comparison of Cloud Database Services
AWS RDS (Relational Database Service), Azure SQL Database, and Google Cloud SQL are the big three when it comes to cloud-based relational databases. They all offer similar core functionalities – managed instances of popular database systems like MySQL, PostgreSQL, and SQL Server – but they differ in pricing models, features, and integrations with other cloud services. AWS RDS, for instance, often boasts a wider range of database engine options and a mature ecosystem of related tools.
Azure SQL Database excels in its tight integration with other Azure services, making it a natural choice for organizations already heavily invested in the Microsoft ecosystem. Google Cloud SQL, while perhaps less feature-rich in some areas, frequently offers competitive pricing and strong performance. The best choice depends heavily on your specific needs and existing infrastructure.
Advantages and Disadvantages of Cloud Databases
Using cloud databases brings several key benefits to the table. Scalability is a huge one; you can easily adjust your database resources (storage, compute power) as needed, scaling up during peak demand and down during slower periods, avoiding the upfront investment and ongoing maintenance of large on-premises hardware. Cost-effectiveness is another plus, as you only pay for what you use, eliminating the need for significant upfront capital expenditure on hardware and software licenses.
High availability and disaster recovery are also greatly simplified by the cloud’s built-in redundancy and failover mechanisms. However, there are downsides. Vendor lock-in is a potential concern; migrating away from a specific cloud provider can be complex and time-consuming. Security is another key consideration; while cloud providers invest heavily in security, you still need to implement appropriate security measures to protect your data.
Finally, network latency can be a factor, particularly if your application users are geographically dispersed and far from the cloud data center.
Migrating an On-Premises Database to the Cloud
Migrating an existing database to the cloud is a multi-step process. It starts with careful assessment – evaluating your current database environment, identifying dependencies, and defining your migration goals. Next comes planning – choosing the appropriate cloud database service, determining the migration strategy (e.g., lift and shift, replatforming, refactoring), and developing a detailed migration plan. The actual migration involves various steps like backing up your on-premises database, setting up the cloud database instance, and transferring the data.
Finally, thorough testing and validation are crucial to ensure everything works as expected in the new environment. Tools and services offered by cloud providers can significantly aid this process, often providing automated migration tools and assistance.
Cloud-Based Database Architecture for an E-commerce Application
Let’s design a cloud database architecture for a hypothetical e-commerce platform. We could use a multi-tier architecture. The presentation tier would be handled by web servers distributed across multiple availability zones for high availability. The application tier would comprise application servers responsible for business logic, potentially using a microservices approach for scalability and maintainability. The data tier would consist of a relational database (e.g., PostgreSQL on AWS RDS) for storing product information, customer data, and order details.
We’d employ a caching layer (e.g., Redis) to improve performance by storing frequently accessed data. For high availability and disaster recovery, we’d leverage the cloud provider’s features, such as read replicas and automated backups. Security would be layered, employing network security groups, database access controls, and encryption both in transit and at rest. This design emphasizes scalability, resilience, and security, key aspects of a successful e-commerce platform.
NoSQL Databases
Okay, so we’ve covered the basics of relational databases. Now let’s dive into the world of NoSQL databases – a whole different beast! They’re becoming increasingly popular, especially with the rise of big data and cloud computing. Think of them as a more flexible, scalable alternative to the traditional relational model.Relational databases, like MySQL or PostgreSQL, organize data into tables with rows and columns, enforcing strict relationships between data.
NoSQL databases, on the other hand, are non-relational, offering more flexibility in how data is structured and accessed. This flexibility comes with trade-offs, of course, but it’s a powerful tool in the right context.
Differences Between Relational and NoSQL Databases
Relational databases excel at managing structured data with well-defined relationships. They use SQL for querying, offering ACID properties (Atomicity, Consistency, Isolation, Durability) for reliable transactions. NoSQL databases, conversely, are schema-less or have flexible schemas. They often prioritize scalability and performance over strict data consistency, utilizing various data models depending on the specific needs. They typically use NoSQL query languages which are often database-specific.
This makes them ideal for handling large volumes of unstructured or semi-structured data.
Types of NoSQL Databases
NoSQL databases come in several flavors, each with its own strengths and weaknesses. Choosing the right type depends heavily on your application’s specific requirements.
- Document Databases: These databases store data in documents, typically JSON or XML. MongoDB is a popular example. Think of it like storing data in a flexible, self-describing format. Each document can have a different structure, making it easy to adapt to evolving data needs.
- Key-Value Databases: These are the simplest NoSQL databases. Data is stored as key-value pairs, like a dictionary. Redis and Memcached are prime examples, often used for caching and session management due to their blazing-fast read and write speeds. They’re not ideal for complex queries, though.
- Graph Databases: These databases excel at representing relationships between data points. Neo4j is a well-known example. Imagine a social network; graph databases are perfect for modeling connections between users, posts, and groups. They are highly efficient at traversing relationships and finding connections.
- Wide-Column Stores: These databases are designed for handling massive amounts of sparse data. Cassandra and HBase are prominent examples. Think of sensor data or time-series data – where you have many columns, but most of them are empty for a given row. They’re highly scalable and fault-tolerant.
Use Cases for NoSQL Databases
NoSQL databases shine in scenarios where relational databases struggle.
- Real-time analytics: Applications requiring immediate insights from large datasets, like fraud detection or stock trading, benefit from the speed and scalability of NoSQL.
- Content management systems (CMS): Handling large volumes of unstructured content like blog posts, images, and videos is well-suited to NoSQL’s flexibility.
- Social media platforms: Managing user profiles, relationships, and content requires a database that can handle massive amounts of data and complex relationships, which is where NoSQL excels.
- Internet of Things (IoT): Processing data from numerous connected devices requires high scalability and the ability to handle diverse data types.
Scalability and Performance Comparison
NoSQL databases generally offer superior scalability and performance compared to relational databases, particularly for horizontal scaling (adding more servers). They’re designed to handle massive datasets and high traffic loads. However, this scalability often comes at the cost of some data consistency guarantees. Relational databases, while offering ACID properties, can struggle to scale horizontally as easily. The best choice depends on the specific application’s needs; high availability and scalability might outweigh the need for strict ACID compliance in many modern applications.
For instance, a social media platform might prioritize fast read speeds for the newsfeed over strict transaction guarantees for every like or comment.
Data Visualization and Reporting
Okay, so we’ve built our database, queried it, and ensured data integrity. Now, what do wedo* with all this awesome data? That’s where data visualization and reporting come in. It’s all about transforming raw data into something understandable and actionable, helping us identify trends, patterns, and insights that might otherwise be buried in spreadsheets. Think of it as giving your data a voice.Data visualization techniques leverage charts, graphs, and maps to represent data visually.
Database software is essential for managing tons of info, right? Think about how much data TurboTax handles; if you’re using turbo tax online , they’re relying on seriously robust database systems to keep your tax info safe and accessible. So yeah, database software is way more important than you might think, even if you’re just filing your taxes online.
This makes complex information much easier to grasp and communicate to others, whether they’re technical experts or business stakeholders. Effective visualizations tell a story, highlighting key findings and making it simple to understand the data’s implications.
Data Visualization Techniques
Various techniques exist for visualizing data, each suited to different data types and analytical goals. Bar charts are excellent for comparing categories; line charts illustrate trends over time; pie charts show proportions; scatter plots reveal correlations between variables; and heatmaps display data density across a matrix. Choosing the right visualization depends on the specific question you’re trying to answer and the type of data you have.
For example, showing sales figures across different regions would benefit from a geographical map, while comparing product performance over several quarters might be best suited to a line chart.
Business Intelligence (BI) Tools
BI tools are software applications designed to collect, integrate, analyze, and present business information. They often include robust data visualization capabilities, allowing users to create custom reports and dashboards. Popular BI tools include Tableau, Power BI, and Qlik Sense. These tools streamline the process of transforming raw data into actionable insights. They offer features like drag-and-drop interfaces for easy report creation, data blending from multiple sources, and sophisticated analytical functions.
For instance, a marketing team might use a BI tool to analyze website traffic data, identify customer segments, and optimize marketing campaigns based on visualized insights.
Sample Report: Hypothetical Sales Data
Let’s imagine a hypothetical database tracking sales of three products (A, B, and C) across two regions (North and South) over three months (January, February, March).
| Product | Region | January | February | March |
|---|---|---|---|---|
| A | North | 100 | 120 | 150 |
| A | South | 80 | 90 | 110 |
| B | North | 50 | 60 | 70 |
| B | South | 40 | 50 | 60 |
| C | North | 150 | 180 | 200 |
| C | South | 120 | 140 | 160 |
A simple report could visualize this data using clustered bar charts, showing sales for each product in each region over the three months. This would immediately highlight which product performed best in each region and how sales trends changed over time.
Interactive Dashboards
Interactive dashboards take data visualization to the next level. They provide a dynamic, real-time view of key performance indicators (KPIs) and allow users to explore data interactively. For example, a dashboard might display sales figures, website traffic, and customer satisfaction scores, all updated in real-time. Users can then filter data, drill down into specific details, and generate custom reports on demand.
This enables faster decision-making and a more proactive approach to business management. Imagine a dashboard showing sales data, allowing users to filter by product, region, and time period, with interactive charts updating in real-time as filters are applied. This provides a highly engaging and informative way to interact with and analyze data.
Final Conclusion
From understanding the fundamental functionalities of database software to mastering SQL queries and navigating the complexities of cloud-based solutions, this exploration has provided a comprehensive overview of this critical technology. By grasping the core concepts of data modeling, security, and efficient database management, you’re now equipped to make informed decisions when selecting and implementing database solutions for any application.
Whether you’re a seasoned developer or just starting your journey into the world of data, remember that the power of information lies in how effectively it’s managed. So go forth and build amazing things!
Essential Questionnaire
What’s the difference between SQL and NoSQL databases?
SQL databases use a structured, relational model, great for well-defined data. NoSQL databases offer more flexibility for unstructured or semi-structured data, scaling better for massive datasets.
How do I choose the right database for my project?
Consider factors like data volume, structure, scalability needs, budget, and your team’s expertise. There’s no one-size-fits-all answer; the best choice depends on your specific requirements.
What are some common database security threats?
SQL injection, unauthorized access, data breaches, and denial-of-service attacks are all significant concerns. Implementing strong authentication, authorization, and encryption is crucial.
Is it difficult to learn SQL?
Not at all! The basics are surprisingly intuitive, and there are tons of online resources and tutorials to help you get started. Practice makes perfect!
What is data normalization?
Data normalization is a process used to organize data to reduce redundancy and improve data integrity. It involves splitting databases into two or more tables and defining relationships between the tables.